Synopsis
When the user performs a search in a ecommerce site, the format of the searchTerm largely decides the relevancy of the search results. To achieve a better relevancy of the search results a series of tokenization can be applied to the fields across which the search is performed.
Use Case:
If the user performs a search for a product number, the result displays the product with the matching part number .
Ex:searchTerm = “USTXBK350”, the application performs a search against the partNumber field and returns the product as search result.
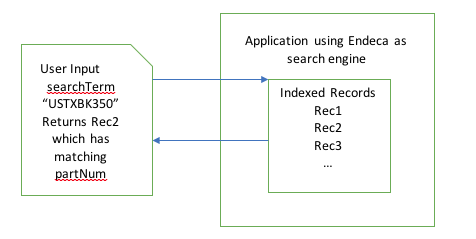
The searchTerm “USTXBK350” matches the partNumber of the Rec1 and returns it as search result.

If the user doesn’t remember the complete partNumber and performs a search with “BK35” ,this might not work as expected.
Solution:
To achieve a partial match , the following options are available:
- Perform a wildcard search– This might fix the problem with a performance trade-off. This might also lead to perform a wildcard search against other fields and qualify as search results.
REC1: Name: TestBK350 partNumber : TX1234 REC2: Name:TestProduct partNumber:USTXBK350 REC3: Name : TestProd3 partNumber: TEST300
If the fields “name” and “partNumber” are made searchable and enabled for wildcard search.The searchTerm would match and return all the records (REC1,REC2 and REC3).Though the products are returned as part of the search results , the relevancy of the search results is compromised.
To fix this we can use tokenization on the partNumber filed.
The following tokenization ways are :
- AlphaNumeric : With this approach we split the partNumber into two parts .For ex: BK350 will be divided into BK and 350.
partNum.split("(?<=\\D)(?=\\d)").
- NGram: the various N-gram approach followed are
generateNGram(partNumbers[i], 3, partNumberTokens); generateNGram(partNumbers[i], 4, partNumberTokens); generateNGram(partNumbers[i], 5, partNumberTokens); generateNGram(partNumbers[i], 6, partNumberTokens); generateNGram(partNumbers[i], 7, partNumberTokens);
We split the partNumber into sequence of characters.
Ex: BK350 with nGram 3 will create a sequence of tokens : BK3,K35,350
With the above 2 tokenization ,the Record will have the following fields and the new filedpartNumberToken is made searchable.
REC1: Name: TestBK350 partNumber : TX1234 partNumberToken: TX partNumberToken 1234 partNumberToken: TX12 partNumberToken:X123 partNumberToken:1234 REC2: Name:TestProduct partNumber:USTXBK350 partNumberToken:USTXBK partNumberToken:350 partNumberToken:USTX partNumberToken:STXB partNumberToken:TXBK partNumberTokenXBK3 partNumberToken:BK35 partNumberToken:K350 REC3: Name : TestProd3 partNumber: TEST300 partNumberToken:TESTBK partNumberToken:300 partNumberToken:TEST partNumberTokenEST3 partNumberTokenST30 partNumberToken:T300
So , now when the search is performed using the searchTerm “BK35” (part of the partNumber) the REC2 finds a match with partNumberToken field and returns the exact product as the result.
